
6TOPS算力驅動30億參數LLM,米爾RK3576部署端側多模態多輪對話
http://www.gjzbw99.com 2025-09-04 13:37 來源:米爾電子
當 GPT-4o 用毫秒級響應處理圖文混合指令、Gemini-1.5-Pro 以百萬 token 上下文 “消化” 長文檔時,行業的目光正從云端算力競賽轉向一個更實際的命題:如何讓智能 “落地”?—— 擺脫網絡依賴、保護本地隱私、控制硬件成本,讓設備真正具備 “看見并對話” 的離線智能,成為邊緣 AI 突破的核心卡點。
2024 年,隨著邊緣 SoC 算力正式邁入 6 TOPS 門檻,瑞芯微 RK3576 給出了首個可量產的答案:一套完整的多模態交互對話解決方案。
 RK3576 多模態純文字:自我介紹
RK3576 多模態純文字:自我介紹
如今,“端側能否獨立運行圖文多輪對話” 已不再是技術疑問,而是工程實現問題。RK3576 通過硬件算力優化與軟件棧協同,將視覺編碼、語言推理、對話管理三大核心能力封裝為可落地的工程方案,而本文將聚焦其多輪對話的部署全流程,拆解從模型加載到交互推理的每一個關鍵環節。
 RK3576 多輪對話:基于歷史回答圖中女孩頭發和衣服分別是什么顏色
RK3576 多輪對話:基于歷史回答圖中女孩頭發和衣服分別是什么顏色
上一次我們詳細講解在RK3576上部署多模態模型的案例,這次將繼續講解多輪對話的部署流程。整體流程基于 rknn-llm 里的多輪對話案例[1]。

RK3576 工作狀態
unsetunset本文目錄unsetunset
一、引言
1.1 什么是多輪對話?
1.2 多輪對話系統鳥瞰:三顆“核心”協同驅動
1.3 核心邏輯:多輪對話的處理流程
二、工程化落地:從源碼到部署的全流程
2.1 依賴環境
2.2 一鍵編譯
2.3 端側部署步驟
三、效果展示:圖文多輪問答
四、二次開發與拓展方向
五、結論與未來發展方向
unsetunset一、引言unsetunset
1.1 什么是多輪對話?
多輪對話(Multi-Turn Dialogue)是指用戶與智能系統通過多輪交互逐步明確需求、解決問題的對話形式。這種交互依賴對話歷史的上下文連貫性,要求系統能夠動態理解用戶意圖、維護對話狀態并生成符合語境的回應。
本質是動態語境下的交互推理,其核心在于通過多輪信息交換逐步明確用戶需求。例如,用戶可能先詢問 “附近有餐廳嗎?”,系統回應后用戶補充 “要適合家庭聚餐的”,系統需結合歷史對話調整推薦策略。
這種交互模式與單輪問答的區別在于:
- 上下文依賴性:每輪對話需關聯歷史信息(如用戶偏好、已確認的細節)。
- 狀態維護:系統需跟蹤對話狀態(如未完成的信息補全),避免重復詢問或信息遺漏。
- 動態意圖調整:用戶可能在對話中修正或細化需求,系統需實時調整響應策略
1.2 多輪對話系統鳥瞰:三顆“核心”協同驅動
RK3576 多模態交互對話方案基于 RKLLM 的核心運作,依賴于圖像視覺編碼器、大語言模型與對話管家這三大模塊的協同配合,三者各司其職、無縫銜接,共同構建起完整的多模態對話能力。
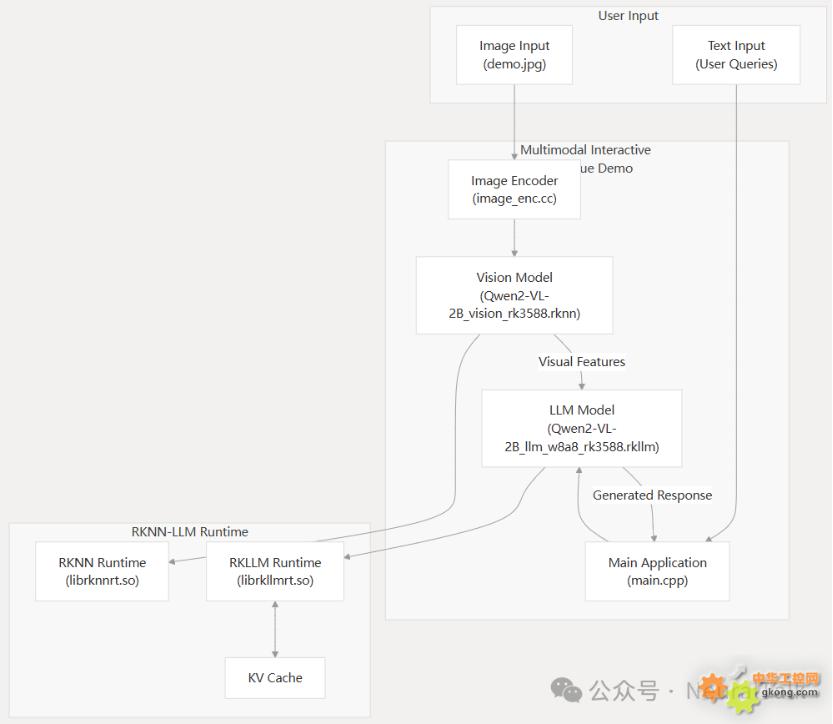 多輪對話系統架構
多輪對話系統架構
1. 圖像視覺編碼器(Vision Encoder)
- 模型選擇:采用 qwen2_5_vl_3b_vision_rk3576.rknn 模型(本文)。
- 核心作用:將輸入圖像壓縮為視覺 token 如 256 個視覺 token,直接輸入至大語言模型中,實現圖像信息向語言模型可理解格式的轉換。
2. 大語言模型(LLM Core)
- 模型選擇:搭載 qwen2.5-vl-3b-w4a16_level1_rk3576.rkllm 模型,采用 W4A16 量化方案(本文)。
- 模型規模:參數規模達 30 億,KV-Cache,為對話推理提供核心的語言理解與生成能力。
3. 對話管家(Dialogue Manager)
基于純 C++實現,采用單線程事件循環機制,承擔著對話流程的統籌調度工作,具體職責包括:
- 多輪對話的 KV-Cache 維護與手動清除;
- Prompt 模板的動態渲染;
- 用戶輸入的解析處理與推理結果的回顯展示。
1.3 核心邏輯:多輪對話的處理流程
該方案的多模態多輪對話 demo,整體遵循“模型加載 → 圖片預處理 → 用戶交互 → 推理輸出”的核心流程,支持圖文一體的多模態對話,適配多輪問答、視覺問答等典型場景。
具體運行機制可拆解為以下步驟:
1. 模型初始化
首先加載大語言模型(LLM),并配置模型路徑、max_new_tokens(生成內容最大 token 數)、max_context_len(最大上下文長度)、top_k、特殊 token 等關鍵參數;隨后加載視覺編碼模型(imgenc),為后續圖片處理做好準備。
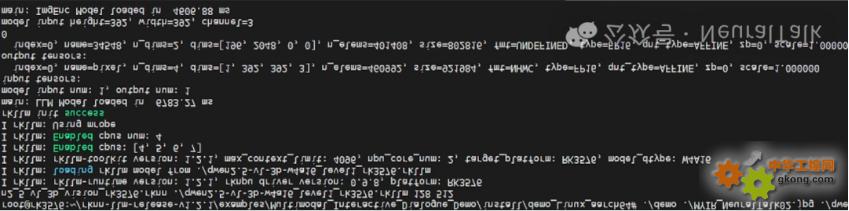 RK3576 平臺運行多模態對話 Demo 的終端日志,顯示視覺與語言模型成功加載,包含模型版本、硬件配置及張量信息,完成多模態交互前的初始化。
RK3576 平臺運行多模態對話 Demo 的終端日志,顯示視覺與語言模型成功加載,包含模型版本、硬件配置及張量信息,完成多模態交互前的初始化。
2. 圖片處理與特征提取
讀取輸入圖片后,先將其擴展為正方形并填充背景色以統一尺寸,再調整至模型要求的 392x392 分辨率,最后送入視覺編碼模型進行處理,生成圖片的 embedding 向量,完成圖像特征的提取。
3. 多輪交互機制
程序會提供預設問題供用戶選擇(官方案例中也有輸入序號,可以快速提問),同時支持用戶自定義輸入,核心交互邏輯通過以下機制實現:
- 上下文記憶
- 通過設置rkllm_infer_params.keep_history = 1,開啟上下文記憶功能,KV-Cache 在顯存中持續追加存儲,每輪對話僅計算新增 token,大幅提升推理效率。使模型能關聯多輪對話內容;
- 若設為 0,則每輪對話獨立,不保留歷史信息,詳見src/main.cpp。
- 歷史緩存清空:當用戶輸入“clear”時,系統調用rkllm_clear_kv_cache(llmHandle, 1, nullptr, nullptr),清空模型的 KV 緩存,重置對話上下文。
- Prompt 工程:動態定義模型“人設”:采用三段式 Prompt 模板,通過rkllm_set_chat_template()動態注入模型,無需重新訓練即可切換人設,支持中英文雙語系統提示。
模板示例如下:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{用戶輸入}<|im_end|>
<|im_start|>assistant
4. 推理與輸出
用戶輸入后,系統先判斷輸入中是否包含<image>標簽:若包含,則將文本與圖片 embedding 結合,啟動多模態推理;若不包含,則進行純文本推理。組裝輸入結構體并傳遞給模型后,推理結果將實時打印輸出。
5. 退出與資源釋放
支持用戶輸入“exit”退出程序,此時系統會自動銷毀已加載的模型,并釋放占用的硬件資源,確保運行環境的整潔。
unsetunset二、工程化落地:從源碼到部署的全流程unsetunset
由于先前我們已經講過環境的部署,如刷機、文件準備等,這里步驟只提出比較關鍵的。工程位于:rknn-llm/examples/Multimodal_Interactive_Dialogue_Demo,下面我們來逐步看下操作步驟。
2.1 依賴環境
方案的編譯與運行需滿足以下依賴條件
- 圖像處理:OpenCV ≥ 4.5
- 視覺模型運行:RKNNRT ≥ 1.6
- 語言模型運行:RKLLMRT ≥ 0.9
2.2 一鍵編譯
針對不同操作系統提供便捷的編譯腳本,我們是 Linux 系統執行./build-linux.sh,編譯結果如下:
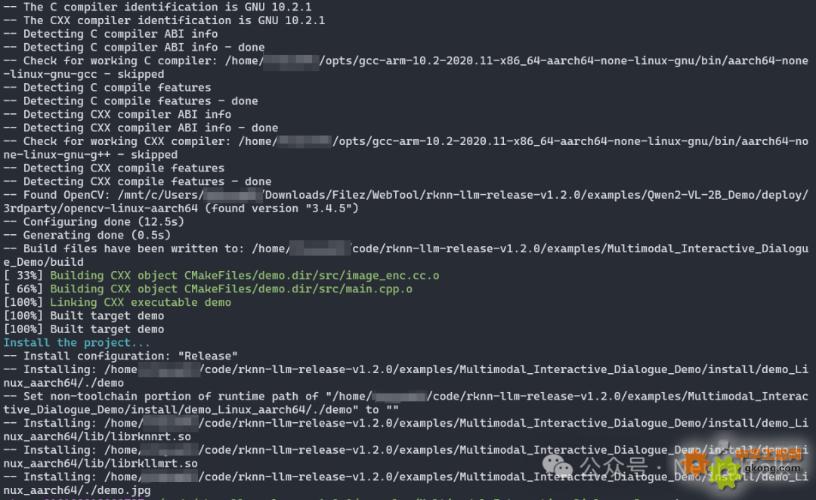
產物目錄為:
install/demo_Linux_aarch64/
├─ demo # 主程序可執行文件
└─ lib # 依賴動態庫
2.3 端側部署步驟
通過 U 盤或者手機將編譯好的產物文件、模型、圖片上傳到開發板上,然后在多輪對話的實例的目錄下,執行以下命令:
cd /data/demo_Linux_aarch64
export LD_LIBRARY_PATH=./lib
./demo demo.jpg vision.rknn llm.rkllm 128 512
其中,部署命令需傳入 5 個核心參數,分別對應:
- image_path:輸入圖片路徑
- encoder_model_path:視覺編碼模型路徑
- llm_model_path:大語言模型路徑
- max_new_tokens:每輪生成的最大 token 數(控制回答長度,避免溢出)
- max_context_len:最大上下文長度(限制歷史對話+當前輸入總長度,防止顯存占用過高)
unsetunset三、效果展示:圖文多輪問答unsetunset
以下面這張圖片作為測試圖片,選擇下面這張圖是因為,有人物、文字、物體、背景等。
 測試圖片2:圖片背景是賽博風格
測試圖片2:圖片背景是賽博風格
我們依次準備的問題如下:
- 這張圖片上有哪些文字信息
- 圖中電路板上的字是什么顏色
- 圖中女孩頭發和衣服分別是什么顏色
- 圖中動漫角色看起來多大年齡
- 圖中背景顏色和女孩眼睛顏色一樣嘛
每輪對話我都有截動態圖,可以感受下體感速度。
 rkllm 模型加載 6.7 秒
rkllm 模型加載 6.7 秒

視覺編碼 rknn 模型進行處理,生成圖片的 embedding 向量,完成圖像特征的提取,4.5 秒
可以明顯感受到這兩個過程是串行的,如果異步處理可以更快。
多輪對話1:這張圖片上有哪些文字信息
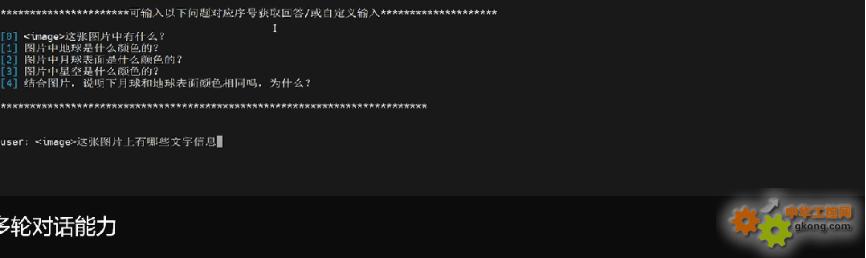
感受一下第一次出詞的耗時
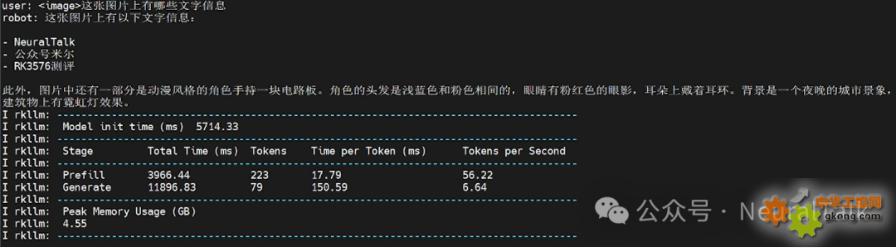
多輪對話1:這張圖片上有哪些文字信息
多輪對話2:圖中電路板上的字是什么顏色
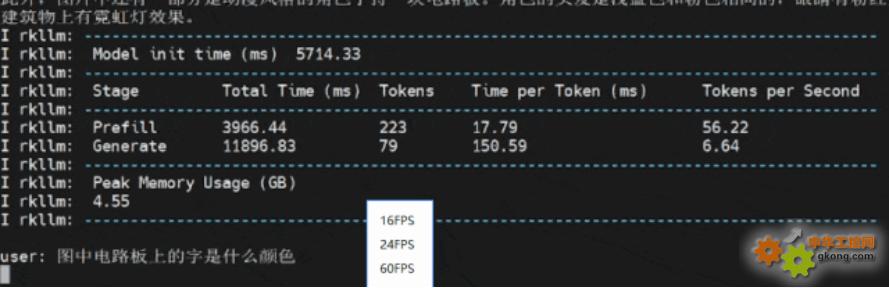
第二次回答就非常快,有一個很短暫的等待時間
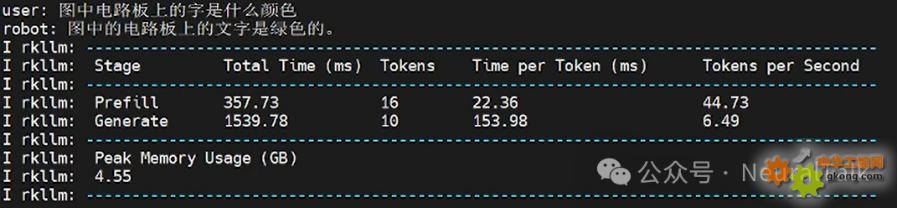
多輪對話2:圖中電路板上的字是什么顏色
多輪對話3:圖中女孩頭發和衣服分別是什么顏色

多輪對話3:圖中女孩頭發和衣服分別是什么顏色,問題基本回答正確,速度和正常閱讀速度差不多
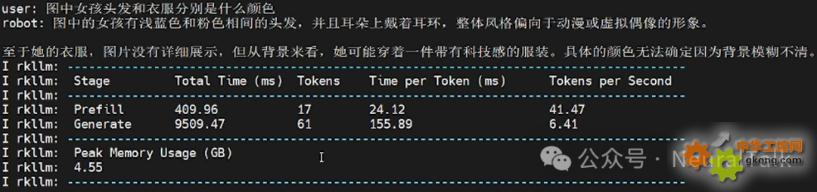
多輪對話3:圖中女孩頭發和衣服分別是什么顏色
多輪對話4:圖中動漫角色看起來多大年齡

多輪對話4:圖中動漫角色看起來多大年齡

多輪對話4:圖中動漫角色看起來多大年齡
多輪對話5:圖中背景顏色和女孩眼睛顏色一樣嘛

記不住了,因為我們設置的rkllm_infer_params.keep_history = 1
代碼中keep_history = 1是開啟上下文記憶功能,即模型應記住前序對話中的關鍵信息,如 “女孩眼睛顏色”“背景顏色”,而 “記不住” 是記憶功能未生效的表現,原因可能除了超過歷史上下文預設的閾值,有時還有可能是因為上下文長度超限(max_context_len=512),或者KV-Cache 清理機制誤觸發等。
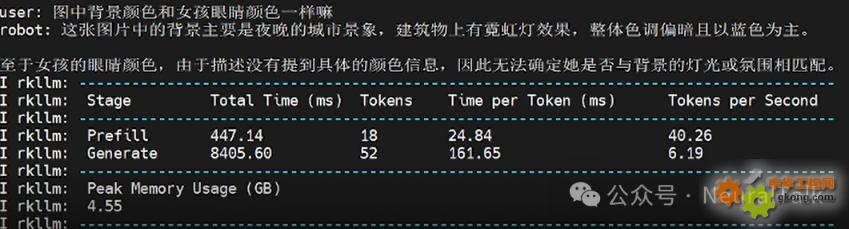
多輪對話5:圖中背景顏色和女孩眼睛顏色一樣嘛
unsetunset四、二次開發與拓展方向unsetunset
方案具備良好的可擴展性,便于開發者根據需求進行二次開發:
- 替換視覺骨干:修改image_enc.cc文件,將輸入分辨率調整為與模型匹配的大小,原因是這些參數與模型的固有結構設計和輸入處理邏輯強綁定,直接影響特征提取的正確性和數據傳遞的一致性。不同的 Qwen2-VL 模型(2B 和 7B)需要代碼中指定IMAGE_HEIGHT、IMAGE_WIDTH及EMBED_SIZE;
- 微調 LLM 模型:借助 RKLLM 工具鏈的 LoRA-INT4 量化支持,在 24 GB 顯存的 PC 上,30 分鐘內可完成 2 億參數模型的增量訓練;
- 接入語音能力:在main.cpp中集成 VAD(語音活動檢測)+ ASR(語音識別,如 Whisper-Tiny INT8)模塊,將語音轉換為文本后接入現有推理流水線,實現“看圖說話+語音問答”的融合交互。
unsetunset五、結論與未來發展方向unsetunset
如果說 “大模型上云” 是 AI 的 “星辰大海”,那么 “多模態落地端側” 就是 AI 的 “柴米油鹽”—— 后者決定了智能技術能否真正滲透到智能家居、工業質檢、穿戴設備等千萬級場景中。RK3576 的多模態交互對話方案,其價值遠不止 “實現了一項技術”,更在于提供了一套 “算力適配 - 工程封裝 - 二次拓展” 的端側 AI 落地范式。
從技術內核看,它通過 “視覺編碼器 + LLM + 對話管家” 的模塊化設計,平衡了推理性能與開發靈活性:W4A16 量化方案讓 30 億參數模型適配 6 TOPS 算力,KV-Cache 動態維護實現多輪對話效率躍升,單線程事件循環降低了資源占用 —— 這些細節不是技術炫技,而是直擊端側 “算力有限、場景碎片化” 的痛點。從工程落地看,一鍵編譯腳本、清晰的參數配置、可復現的部署流程,讓開發者無需深耕底層優化即可快速驗證場景,大幅縮短了從技術原型到產品的周期。
展望未來,這套方案的演進將圍繞三個方向深化:
- 其一,算力效率再突破—— 通過異步模型加載、NPU 與 CPU 協同調度,進一步壓縮首輪推理延遲,適配對響應速度敏感的車載、醫療等場景;
- 其二,多模態融合再升級—— 在圖文基礎上集成語音、傳感器數據,實現 “看 + 聽 + 感知” 的跨模態對話;
- 其三,生態適配再拓展—— 支持更多開源多模態模型的快速移植,形成 “芯片 - 工具鏈 - 模型” 的協同生態。
當 RK3576 證明 “端側能跑好轉好多模態對話” 時,邊緣 AI 的競爭已從 “能否實現” 轉向 “如何更優”。而這套方案的真正意義,在于為行業提供了一塊 “可復用的基石”—— 讓更多開發者無需重復造輪子,只需聚焦場景創新,就能讓 “離線智能” 從實驗室走向量產貨架,最終讓 “AI 就在身邊” 成為無需網絡支撐的常態。
相關新聞
- ? 直播預告 | 恩智浦技術日巡回研討會:技術盛宴,“云端”開席!
- ? 米爾發表演講,并攜瑞薩RZ產品亮相2025 Elexcon深圳電子展
- ? 12路1080P高清視頻流,米爾RK3576 開發板重塑視頻處理極限
- ? 如何在米爾RK3576開發板上板端編譯OpenCV并搭建應用
- ? 如何在RK3576開發板上運行TinyMaix :超輕量級推理框架--基于米爾MYD-LR3576開發板
- ? RKDC2025 丨米爾亮相第九屆瑞芯微開發者大會,共繪工業數智新圖景
- ? 米爾將出席瑞芯微第九屆開發者大會
- ? 如何部署流媒體服務實現監控功能--基于米爾TI AM62x開發板
- ? 米爾出席2025安路科技FPGA技術沙龍
- ? 新品!米爾NXP i.MX 91核心板開發板,賦能新一代入門級Linux應用
編輯精選


